はじめに
以前の記事で、複数のRhinoファイルに複数の Grasshopper ファイルを実行する方法(N 対 M の関係)が報告されています。
実際にこの仕組みを普段の業務で運用してみると、まず1つ分かりやすい課題が見つかりました。この課題に関してはすぐに改善できるアイデアがあり実際に実装してみたので、今回の記事ではそれについての報告を行います。
課題
過去の報告の時点では、ライノデータを入れたフォルダと、 gh データを入れたフォルダを指定し、そのフォルダは一律で処理という想定をしていました。
が、実際に業務で使ってみると共通で使える gh を様々なフォルダに置く必要があるのか?というような課題が見つかりました。
例えば、生産設計フェーズでのモデリングでは、ちょっとしたバリエーションや役物の処理により、gh を別ファイルとして書き分ける場合があります。そのような場合に、過去の記事のやり方の通りではフォルダと実行される gh が紐づいているため、共通の処理は複製が必要となり少々不便だと分かりました。
図で書いてみると下記のような状態です。
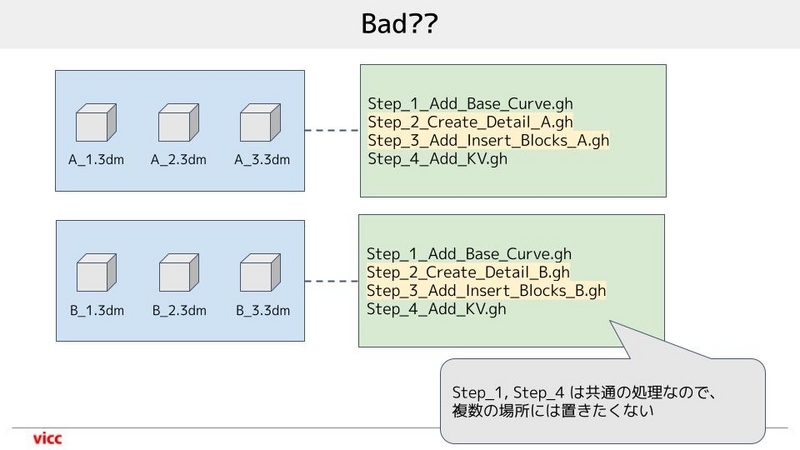
具体的に説明をすると、共通の処理もある A タイプの形状のバラファイルとB タイプの形状のバラファイルのそれぞれのフォルダに対して、それぞれに gh を入れたフォルダを作っています。この場合、共通の処理の gh (図でいうと Step_1 や Step_4)をどちらかで変更した時に、もう一方のフォルダに複製を忘れると大変なことになります。
この図では2つのフォルダになっていますが、これが 3つ、4つ、5つ、、、となった場合、絶対に作業漏れが発生します。
以前のリサーチでは技術的な検証から手を付けていたので、実運用に対しては課題が見つかるのは当然です。業務改善チャンスととらえて解決策を考えます。
解決策
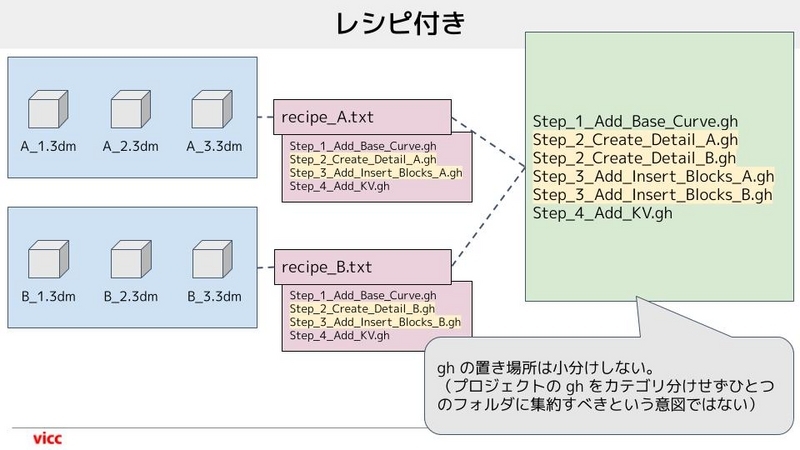
フォルダと実行される gh が紐づけない方法として、下の図のようなものを考えました。アイデアとしては makefile から着想を得ています。
ライノのフォルダと、それに対して実行する gh ファイルを明示したテキストファイル(以後、レシピと呼びます)を紐づけることで、gh ファイルの細かなフォルダ分けを避けています。
Makefile とは(IT 用語辞典)
e-words.jp
技術検証
以下、動作環境は下記のとおりです。
- Windows10
- Rhinoceros 7
- Grasshopper 1.0.0007
- Elefront_Beta, Version=5.1.2.0
単純な文字列処理なので技術的な懸念はありませんが、まず手始めにレシピを読み込んで、gh フォルダから適切なものを探して、順次実行する小さなプログラムを書いてみます。
プログラムを書きながら、ダミーデータを作成してみると、レシピ内に書かれているが gh フォルダには存在しない場合は処理を始める前にプロセスを止めたいと気が付きました。 そのために、最初にレシピと gh フォルダをすべて照合し、その後連番処理を実行するというプログラムとしています。プログラム内の (1) の箇所でチェックを行って、gh ファイルがなければ処理を終えます。
# -*- coding: utf-8 -*- import os import Rhino import rhinoscriptsyntax as rs import scriptcontext as sc def get_GH_file(_dir): path_list = [] for root, dirs, files in os.walk(_dir, topdown=False): for name in files: path = os.path.join(root, name) path = str(path) if path.endswith(".gh"): path_list.append(path) return path_list def read_recipe(file_path): recipes = [] with open(file_path) as f: all_ = f.read() elms = all_.split('\n') for elm in elms: if elm.endswith(".gh"): recipes.append(elm) return recipes gh = Rhino.RhinoApp.GetPlugInObject("Grasshopper") sc.doc = Rhino.RhinoDoc.ActiveDoc gh_folder = rs.BrowseForFolder(message="Select_GH_Folder") gh_files = get_GH_file(gh_folder) # print(gh_files) recipe_path = rs.OpenFileName(title="Select_Recipe") print("Recipe Name : {}".format(os.path.basename(recipe_path))) recipes = read_recipe(recipe_path) # print(recipes) ### (1) Check, gh all exist for recipe in recipes: exit_flag = False for ghfile in gh_files: if recipe in ghfile: exit_flag = True if exit_flag == False: print("Error : {} does not exit gh_folder".format(recipe)) exit() ### (2) Multi GH Run with Recipe for recipe in recipes: for ghfile in gh_files: if recipe in ghfile: ### Dummy GH RUN print("Running :{}".format(ghfile))
予想通り、問題なく実装できました。
一応プログラムの詳細について触れておきます。
- チェック段階と実行段階で、同じループを2度しているので美しい実装ではないですが、たかだが数十のテキストのマッチングなので計算コストはほぼゼロなのでこのまま行きます。
- RhinoPython から gh ファイルの実行は過去記事の段階で確認済みなので、ここでは print 文を用いた疑似的な処理で済ましています。
前回の手法との統合
ここから本題です。
上で書いたレシピを処理する部分を、前回の記事で紹介されているプログラムと統合します。
貼り合わせて10行くらい書き換えるだけなので、特に解説も無しでプログラムを貼っておきます。コメントちゃんと書けよと言われそうですが、関数の名前で表現されている以上のことは何もしていないのでコメントは少な目です。
# -*- coding: utf-8 -*- import os import Rhino import rhinoscriptsyntax as rs import scriptcontext as sc def get_Rhino_file(_dir): path_list = [] for root, dirs, files in os.walk(_dir, topdown=False): for name in files: path = os.path.join(root, name) path = str(path) if path.endswith(".3dm"): path_list.append(path) return path_list def get_GH_file(_dir): path_list = [] for root, dirs, files in os.walk(_dir, topdown=False): for name in files: path = os.path.join(root, name) path = str(path) if path.endswith(".gh"): path_list.append(path) return path_list def read_recipe(file_path): recipes = [] with open(file_path) as f: all_ = f.read() elms = all_.split('\n') for elm in elms: # print(elm) if elm.endswith(".gh"): recipes.append(elm) return recipes def run_GH(gh_file): gh.LoadEditor() gh.CloseAllDocuments() gh.ShowEditor() gh.OpenDocument(gh_file) gh.AssignDataToParameter("RhinoPython_bake", True) gh.RunSolver(True) def loop_GH(gh_files, recipes): ### (2) Multi run for recipe in recipes: for gh_file in gh_files: if recipe in gh_file: run_GH(gh_file) gh.CloseAllDocuments() gh.HideEditor() def open_close(Rhino_file, GH_files, recipes): rhino_file = '"' + Rhino_file + '"' rs.Command('_-Open {}'.format(rhino_file)) loop_GH(GH_files, recipes) rs.Command("_Save") gh = Rhino.RhinoApp.GetPlugInObject("Grasshopper") sc.doc = Rhino.RhinoDoc.ActiveDoc ### Init rs.Command("-New \"Large Objects - Millimeters.3dm\"") ### (0) Input rhino_folder = rs.BrowseForFolder(message="select_Rhino_Folder") rhino_files = get_Rhino_file(rhino_folder) print("Rhino Folder : {}".format(os.path.basename(rhino_folder))) gh_foloder = rs.BrowseForFolder(message="Select_GH_Folder") gh_files = get_GH_file(gh_foloder) recipe_path = rs.OpenFileName(title="Select_Recipe") recipes = read_recipe(recipe_path) print("Recipe Name : {}".format(os.path.basename(recipe_path))) ### (1) Check, gh all exist for recipe in recipes: exit_flag = False for ghfile in gh_files: if recipe in ghfile: # print(ghfile) exit_flag = True if exit_flag == False: print("Error : {} does not exit gh_folder".format(recipe)) exit() ### (2) Sequential opetation for rhino_file in rhino_files: open_close(rhino_file, gh_files, recipes)
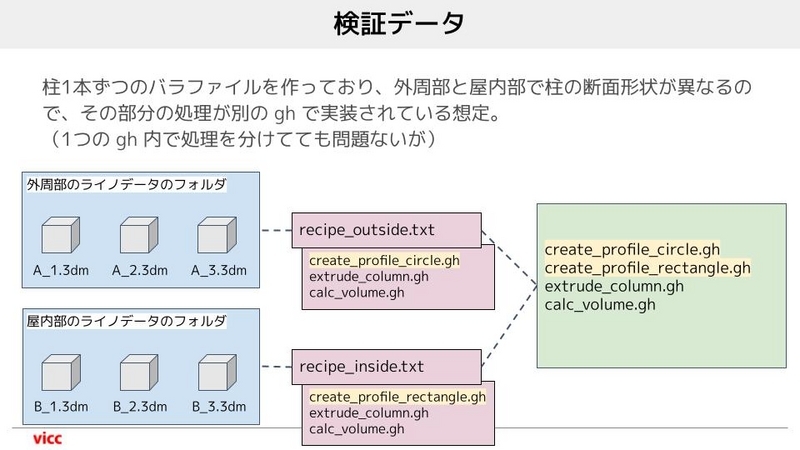
検証用のデータとして、仮想のプロジェクトデータを作成しました。想定のタスクは以下のようなものがあります。
- 外周部と屋内部で柱の断面形状が異なっている。
- 施工のために部材の重量を調べたい(ここでは体積を測っています) 。
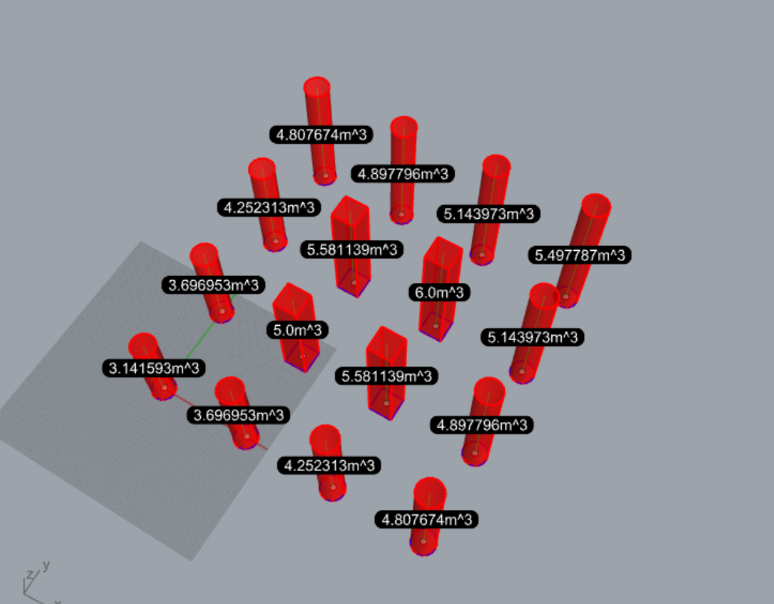
予想通り動作しています。検証に使ったデータを一式で、こちらにアップしておきます。
副次的な発見。新しい研究テーマになるか?
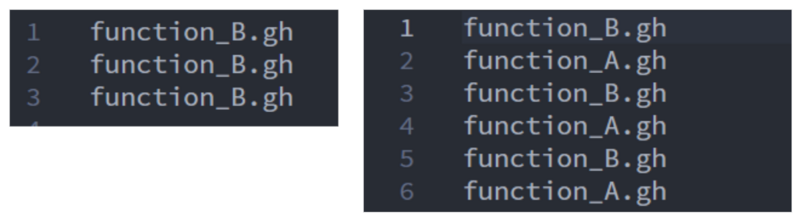
前回の手法の改善をということで手を付けていますが、レシピで指定することにより、1個/複数の gh を繰り返しで実行することができるのではないかと気が付きました。
これによって、例えば移動と距離計測の2つの gh を交互に実行するフィードバックループのような処理が簡単に実装できるのではないかと予想しています。
何の業務で使うか思いついているわけではないですが、ほのかにブレイクスルーの香りを感じます。
まとめ
今回の記事では、過去に提案された手法の発展形を示しました。自分が困った内容を隙間で素早く調査を終えることができたので、実際のプロジェクトで早く使ってみたいです。
業務の中での課題を見つける → 調査&提案(以前の記事) → 業務に取り入れてみて改善箇所を見つける → 調査&提案(今回の記事)という、ザ・業務改善のサイクルが回せた気がします。課題の難易度と自分のスキルセットの相性が良かっただけなので、毎回こうはいかないとは思いますが、取り組みは続けていきたいです。
さて vicc では、改善のサイクルをガシガシ回したいやる気溢れるエンジニアを募集しています。興味を持たれた方は下記よりお問い合わせください!
(終わり)